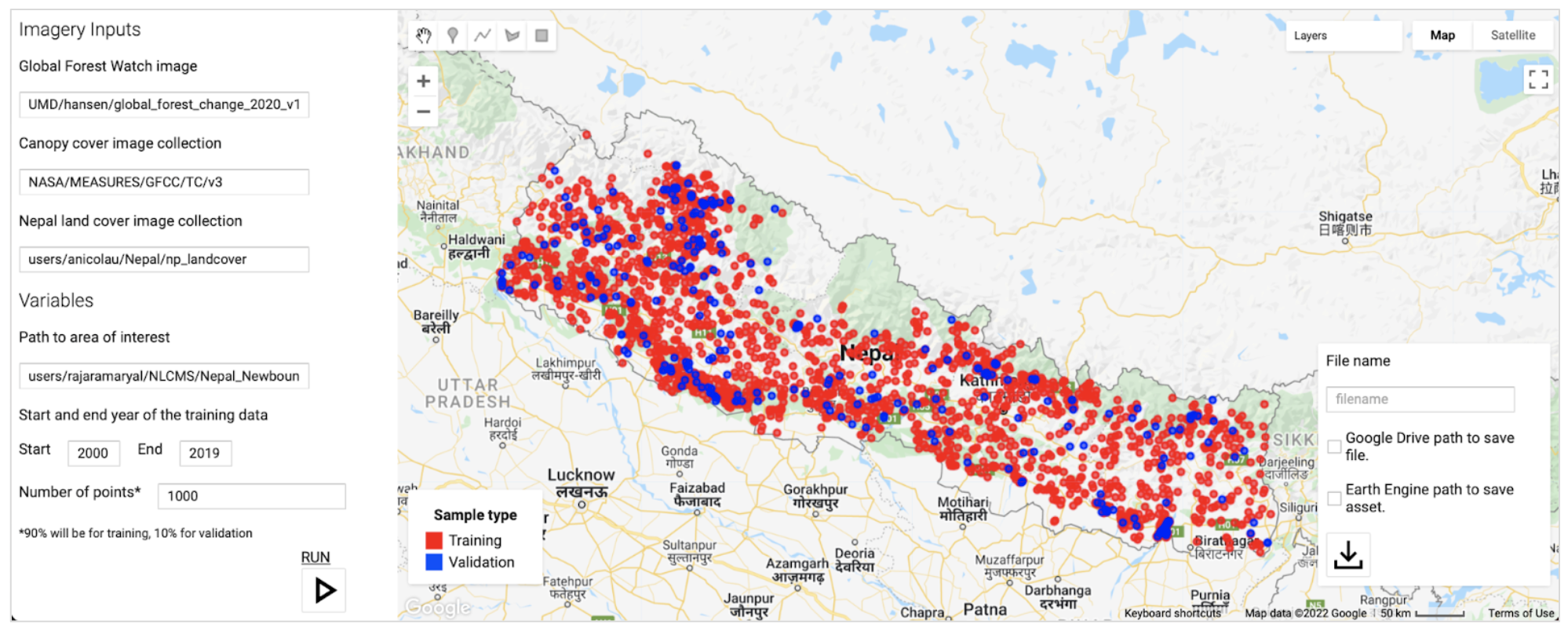
A sample based approach will be used to complete area estimation. This approach is preferred over pixel-counting methods because all maps have errors. Using pixel-counting methods will produce biased estimates of area, and one cannot know whether these are overestimates or underestimates for each strata. Sample based approaches create unbiased estimates of area and the error associated with your map. The agreement map will be used to help select a random subset of the points that are representative of the landscape. The goal is to ensure that no strata is undersampled.
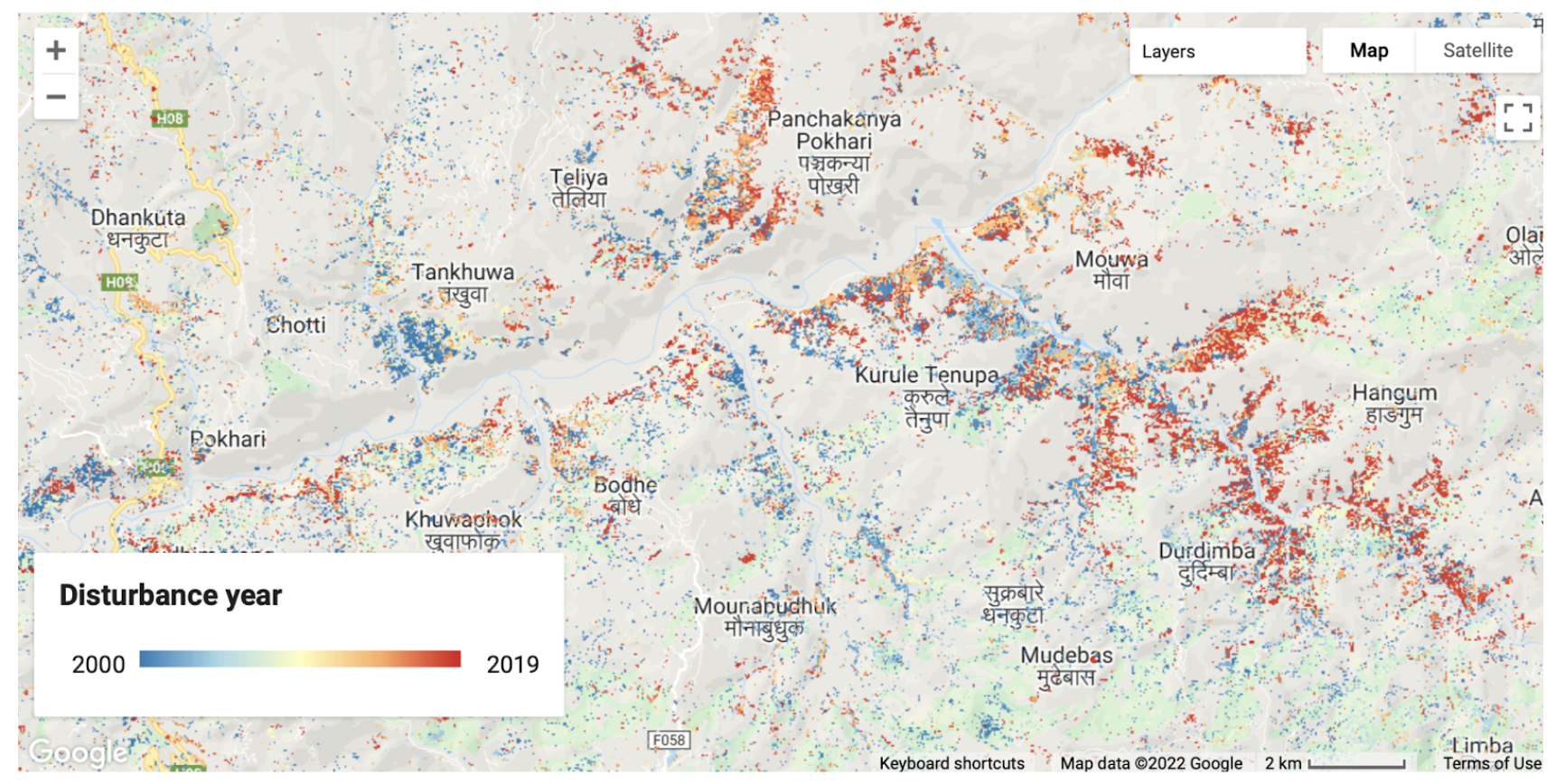
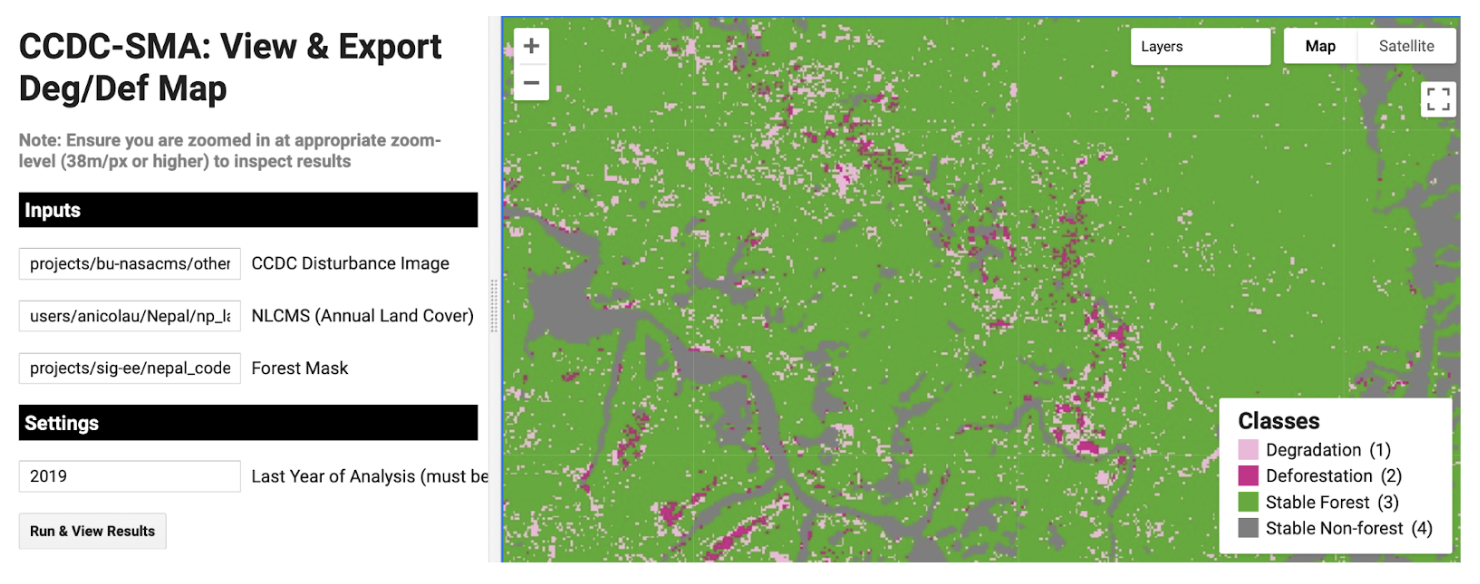
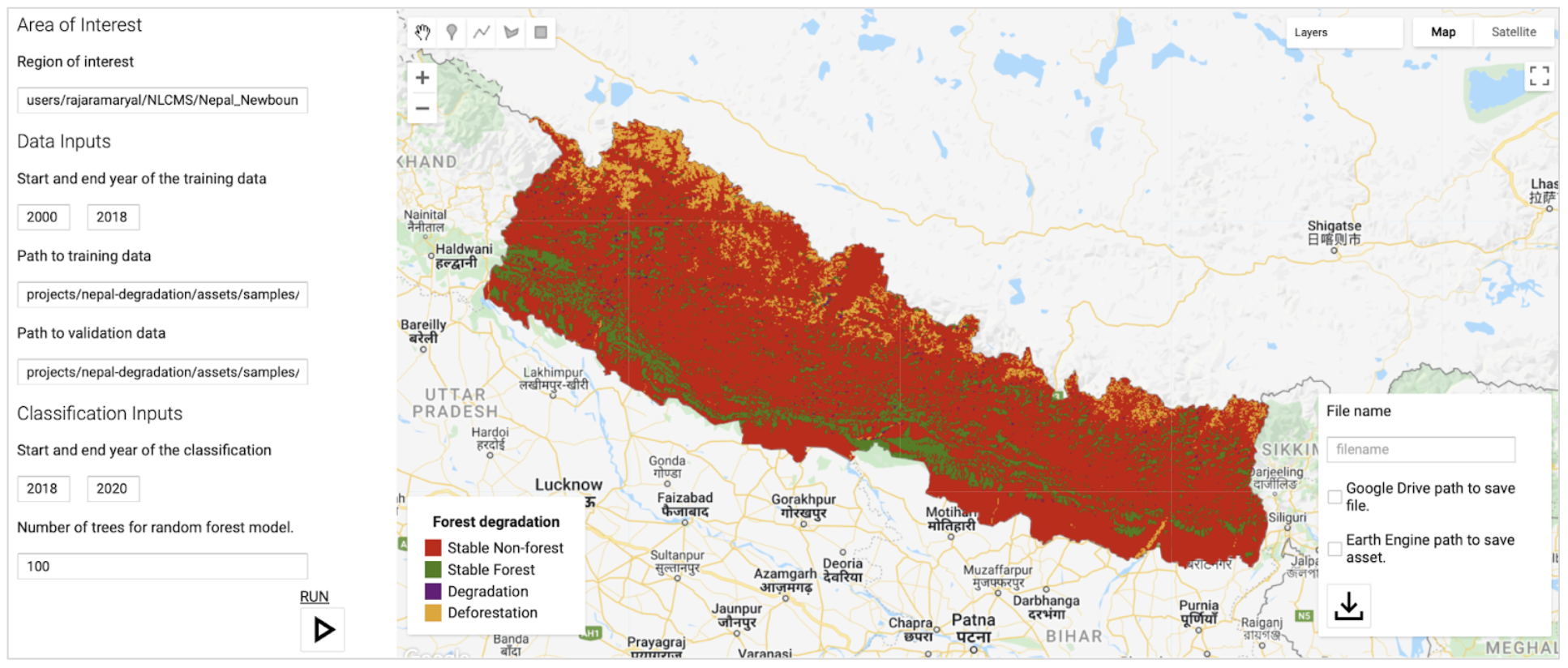
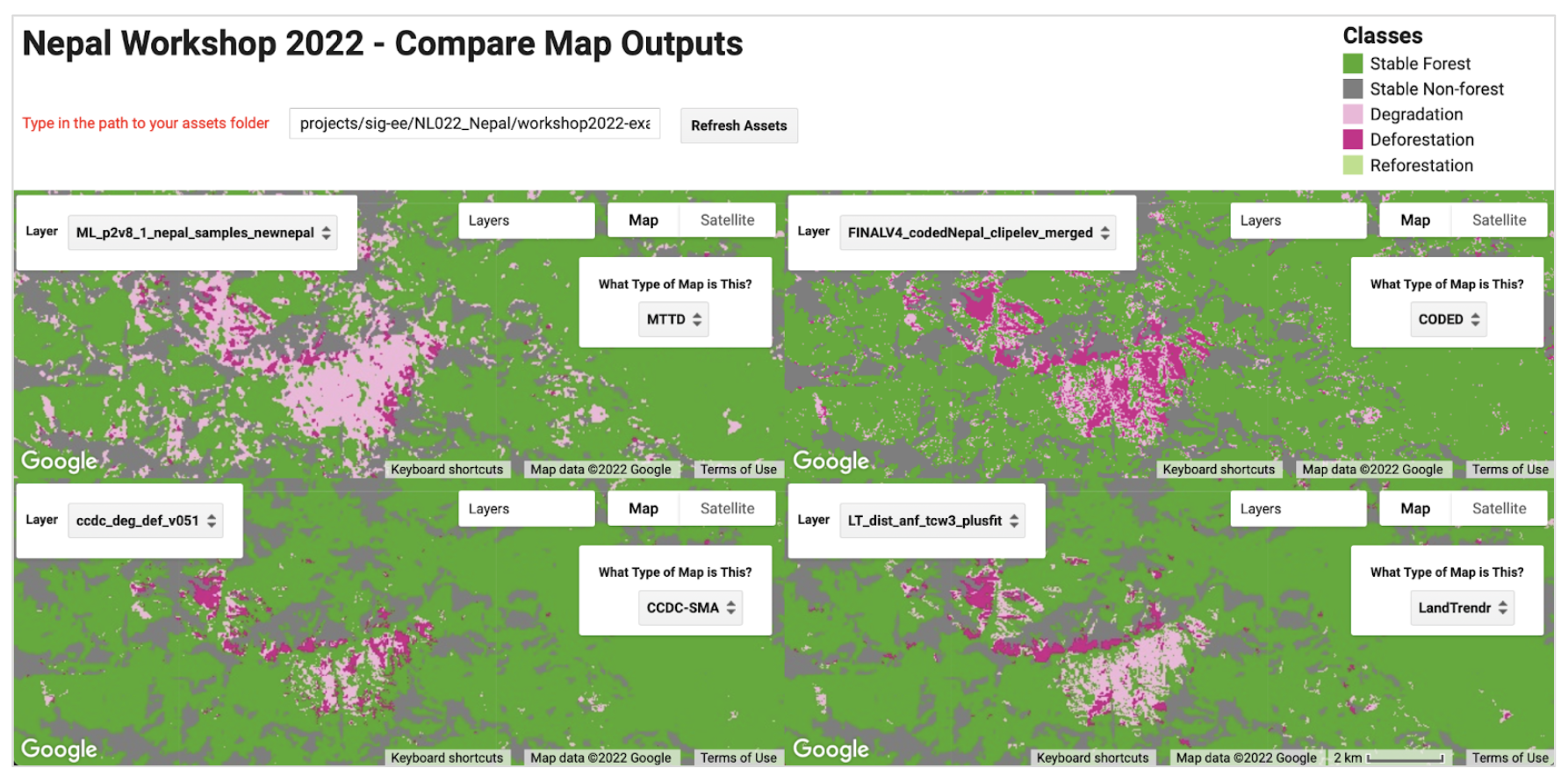
To ensure that the degradation and deforestation areas were very well sampled for the unbiased area estimation, an agreement map generated from the final results of all four methods will be used for sample design. The final results from this step will be a pixel-count of the agreement strata and the agreement map, which will be used in the next stage. The resulting strata of this tool will be anywhere 1-4 algorithms agreed there was a certain kind of change event or stable forest/nonforest, anywhere the different algorithms labeled different types of change events, anywhere all 4 algorithms labeled nonforest, and anywhere all 4 algorithms labeled forest. Counting the pixels per strata will be Page 1 of the tool.
Final strata values for the agreement map and their human-readable labels are… 1:LOSS, 2:DEG, 3:GAIN, 4:ComboChange, 5:Nonforest, 6:Forest
The number of points randomly selected will depend on the relative area available in each strata, the human resources available to do interpretations, and a target standard error. The linked spreadsheet contains equations needed to calculate the ideal sample size in order to hopefully achieve the target standard error. This analysis should be completed between Page 1 and Page 2 of the 1_MakeAgreementMap_Nepal tool. The total number of points could be decreased if it is deemed too large a sample to be collected with existing resources, or increased if more points are needed after QA/QC.
Once you calculate the total number of samples you must distribute them across the strata. If with a proportional distribution of the points to each strata, one or more of the strata is allocated too few samples, you should require a minimum sample size for these strata, and then proportionally distribute the remaining points to the larger strata. These numbers generated in the spreadsheet can then be input used to complete Page 2 of the 1_MakeAgreementMap_Nepal tool and export a random set of sample points.